How IPFS is taking on HTTP
At Novoda, we’ve been investigating products that preserve user privacy – and one that’s caught our attention is IPFS.
So, What is IPFS?
Here’s the definition provided by Wikipedia: “IPFS is a protocol and peer-to-peer network for storing and sharing data in a distributed file system”
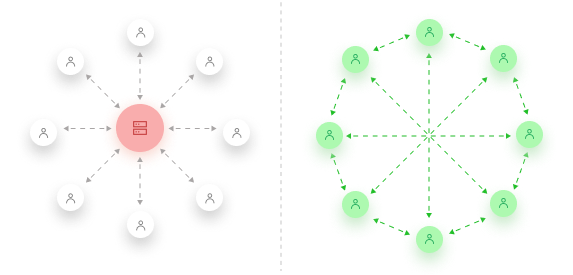
The way we currently share data means that we rely on a centralised server; one that is owned by a single entity, which many people connect to in order to receive some data.
Imagine opening a URL on your phone to download a video, the server that hosts that content may be hundreds of miles away; it may use a lot of bandwidth, data and time depending on the size of the video. If you then wanted to watch it on your computer it is likely you will open the same URL to download the same video again.
There is a better way of sharing this data!
Enter IPFS.
How does it work?
A device connected to IPFS is known as a node, it could be your phone or your desktop – anything capable of sending/receiving data.
The proposal of IPFS is to remove the centralised server and create a decentralised network of nodes. This means that we abandon the concept of using a URL to retrieve data from a server but instead have potentially thousands of nodes across the world, capable of storing and sharing data between each other.
From the previous example, once your phone has received that video file, you would be able to open the file on your computer and download the contents directly from your phone!
A huge advantage of IPFS is that a file may not necessarily be stored on one node; there may be many nodes storing small pieces of that file. This means that instead of retrieving the file from one location, you actually retrieve the file from multiple nodes at once, massively reducing bandwidth.
…Still not convinced?
If you’re a cynic like me, you’ll be asking the following:
Q: What if a node fails during a download?
A: The data will be stored multiple times across many nodes, if one fails we’ll use with another!
Q: What if all of the nodes lose a piece of data?
A: This can happen, especially with old files; File pinning and Filecoin are options and will be discussed below.
Q: How do I actually retrieve a file without a URL?
A: With content addressing.
Instead of connecting to a URL (URL addressing), IPFS will retrieve the data from any nodes that are hosting content with the specified content address. The content address of a file is generated from the files content so that any change to the content results in a new address. The InterPlanetary Name System (IPNS) allows you to create a second more permanent address to a file that does not change when the content is updated.
Persistence
I mentioned two ways to keep data persistent; file pinning and Filecoin. File pinning is a very simple concept, you can pin content to a node so that it will be permanently stored and ignored from any garbage collection.
Filecoin was created by Protocol Labs, the creators of IPFS, to incentivise the network and add resilience. It is a storage service backed by IPFS where users can buy and sell storage space in exchange for the Filecoin currency (FIL). When you store data via Filecoin it will ensure that your data is stored on multiple nodes to avoid any data loss as Filecoin can track how many nodes are hosting a piece of data.
So, is this the future of file storage?
IPFS and Filecoin are critical for the next iteration of the internet AKA web3 and technologies such as blockchain are supported by them. We’re exploring the future of the mobile landscape and believe that IPFS has potential on the mobile platform. What do you think?
If you want to share your thoughts with us, you can continue the conversation on the Novoda Twitter here.
Thanks for reading!